Puppeteer是一个流行的Node.js库,在开发者中广泛使用的用于网页爬取和自动化任务的工具。本文将介绍如何使用puppeteer模块实现爬取网页图片链接并使用axios下载到本地的方法。
1.puppeteer介绍
puppeteer模块:Puppeteer 是一个 Node 库,它提供了一个高级 API 来通过 DevTools 协议控制 Chromium 或 Chrome。你可以在浏览器中手动执行的绝大多数操作都可以使用 Puppeteer 来完成!
参考文档:Puppeteer中文文档
2.配置相关属性并创建实例
// 配置浏览器宽度高度以及其他参数
const options = {
defaultViewport: {
width: 1920,
height: 1080 // 懒加载图片时可能会导致页面高度不够 需要设置
},
headless: false, // 打开浏览器
// devtools: true, // 是否打开Devtool,如果设置为true,headless将强制为false
// slowMo:1000 // 慢慢加载
}
const browser = await puppeteer.launch(options); // 打开浏览器
const page = await browser.newPage(); // 创建一个新的页面
// 目标链接地址
const url ='https://image.baidu.com/search/index?tn=baiduimage&ps=1&ct=201326592&lm=-1&cl=2&nc=1&ie=utf-8&dyTabStr=MTEsMCw0LDYsMywxLDUsMiw4LDcsOQ%3D%3D&word=%E9%A3%8E%E6%99%AF';
await page.goto(url); //跳转到指定页面
3.获取图片dom元素
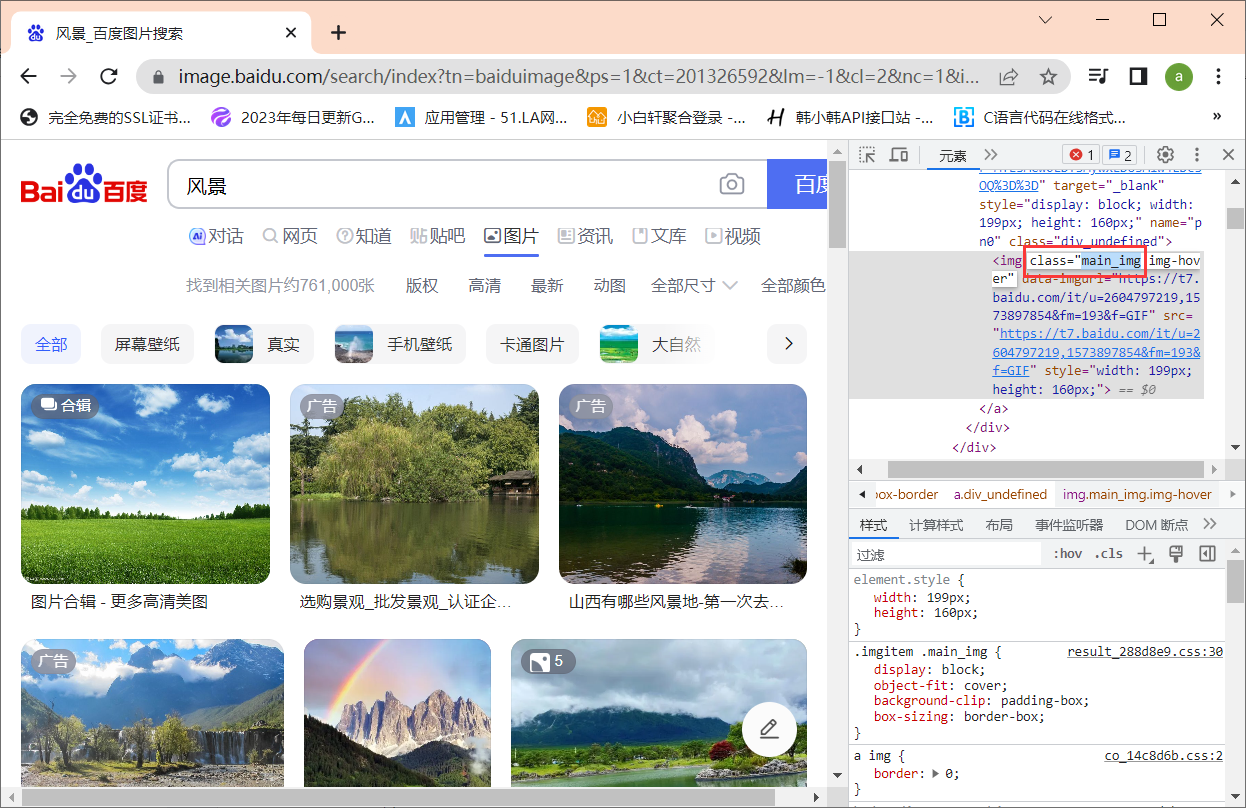
如图所示,此页面中的图片元素都有着同一个类名main_img,我们便可以直接获取到类名为main_img的dom元素(其它任何页面均由此分析,只需要找到图片所对应的dom元素即可):
//自定义事件 获取页面中 class='main_img' 的标签并解析出 url 地址
let urlList = await page.$$eval('.main_img', imgs => {
let urlList = [];
imgs.forEach(img => {
urlList.push(img.src);
})
return urlList;
})
4.监听页面请求事件
在上面代码中,我们可以获取到当前页面的所有图片链接。但是如果我们下滑加载更多,加载后的图片并不会被我们获取到。这时候我们就需要监听页面的请求事件,因为所有的图片肯定是来自于网络请求,我们可以在监听到页面请求时触发自定义函数,解析出图片链接数组。
// 页面发送请求触发该事件
page.on('request', () => {
let urlList = await page.$$eval('.main_img', imgs => {
let urlList = [];
imgs.forEach(img => {
urlList.push(img.src);
})
return urlList;
})
})
由于请求的数量过多,我们没必要每一次都去获取一遍dom元素,可以使用防抖技术在最后一次请求后的一段时间再执行操作。
let timer = null; // 定时器 用于防抖技术
page.on('request', () => {
// 使用防抖技术 在请求结束3秒后执行自定义函数
clearTimeout(timer);
timer = setTimeout(async () => {
//自定义事件 获取页面中 class='main_img' 的标签并解析出 url 地址
let urlList = await page.$$eval('.main_img', imgs => {
let urlList = [];
imgs.forEach(img => {
urlList.push(img.src);
})
return urlList;
})
}, 3000)
})
5.使用axios下载图片
使用 axios 封装一个图片下载的函数:
// 当使用 axios 请求图片时,设置返回的类型为二进制:responseType : "arraybuffer";
// 使用 fs.writeFile() 方法下载图片时,同样设置为二进制的格式:'binary'
const axios = require('axios')
const fs = require('fs')
// 批量下载图片到指定文件夹中
// 图片链接数组 文件名 索引
function downloadImg(urlarr, dir, index) {
// 如果还有图片资源,则继续下载 递归出口
if (index >= urlarr.length) {
console.log("已下载完所有图片");
return;
}
let url = urlarr[index];
axios({
method: 'get',
url,
responseType: 'arraybuffer'
})
.then(res => {
// 下载当前图片文件到文件夹中
fs.writeFile(`${dir}/${index+1}.png`, res.data, 'binary', (err) => {
if (err) {
console.log(`第 ${index+1} 张下载失败`, err);
} else {
console.log(`第 ${index+1} 张下载成功`);
}
// 递归调用
downloadImg(urlarr, dir, index + 1);
})
})
}
在上述案例中使用:
let timer = null;
let cnt = 0; // 下载图片数量
// 页面发送请求触发该事件
page.on('request', () => {
clearTimeout(timer);
timer = setTimeout(async () => {
let urlList = await page.$$eval('.main_img', imgs => {
let urlList = [];
imgs.forEach(img => {
urlList.push(img.src);
})
return urlList;
})
if (urlList.length > cnt) {
// 批量下载 url 链接数组中的图片
await downloadImg(urlList, './image/', cnt);
cnt = urlList.length;
}
}, 3000)
})
至此,本案例就已经实现完成。对于不同的网页,区别就在于dom元素的不同,需要开发者打开控制台找到相应元素的dom元素并提取出想要的信息。






