学习puppeteer也有一段时间了,不得不说puppeteer确实是一个非常强大的工具,今天将实现最后一个小案例:使用puppeteer爬取微博热搜并配合node-schedule实现定时爬取的功能。实现效果参考本站右侧菜单栏。
相关前置文章:
使用node-schedule模块实现Node.js定时任务管理
Node.js使用puppeteer+axios爬取页面图片链接并下载图片到本地
Node.js使用puppeteer+axios爬取页面图片链接并下载图片到本地
1.puppeteer-core与puppeteer
这里为什么首先要提出puppeteer-core这个新的模块呢?其实是因为在服务器端开发时puppeteer会因为兼容性问题不太好用,因此我们可以使用puppeteer-core配合本地的Chrome来使用。
简单来说puppeteer = puppeteer-core + Chrome。
2.服务器下载Chrome
由于使用的是puppeteer-core,需要手动下载Chrome。
以centos系统为例,使用如下指令安装:sudo yum install chromium
3.打开浏览器并设置为无头模式
由于在服务器端并不需要可视化界面,因此可以将headless设置为true。要注意的是puppeteer-core中需要手动配置Chrome的路径:
const weiboHotUrl = "https://s.weibo.com/top/summary?cate=realtimehot"; // 微博链接
const browser = await puppeteer.launch({
headless: true,
// executablePath: "C:\\Program Files\\Google\\Chrome\\Application\\chrome.exe", // Windows操作系统下chrome安装路径
executablePath: '/usr/bin/chromium-browser', // Linux操作系统下chrome安装路径
args: ['--no-sandbox'] // 设置其他参数 禁止沙盒模式
});
const page = await browser.newPage();
await page.goto(weiboHotUrl);
4.分析微博页面dom结构
打开浏览器开发者工具,在页面结构中提取出微博热搜相关dom结构,只要是能准确定位到所需要的dom结构即可。
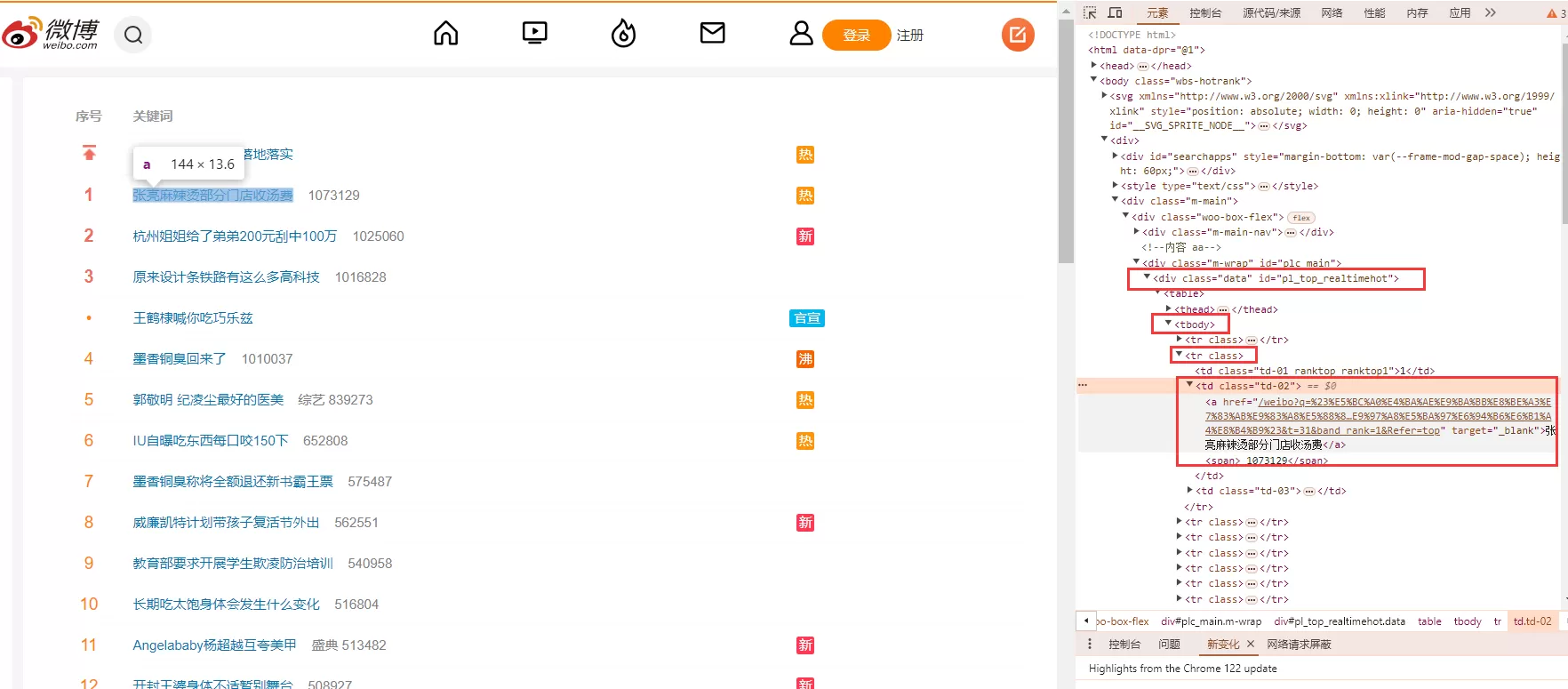
await page.waitForSelector('#pl_top_realtimehot tbody>tr .td-02'); // 等待此标签的渲染
const tds = await page.$$('#pl_top_realtimehot tbody>tr .td-02'); // 获取到dom集合数组
5.整理所需要的数据
const list = await Promise.all(tds.slice(1).map(async (td, i) => { // 数组第一项不是热搜内容
const list1 = await td.$eval('a', a => ({
title: a.innerText, // 标题
url: `https://s.weibo.com${a.getAttribute('href')}`, // 链接
}));
const list2 = await td.$eval('span', span => ({
hot: span.innerText // 热度
}));
return {
id: i + 1,
...list1,
...list2,
};
}));
6.封装成函数
// 爬取微博热搜
const get_weibo_hot=async ()=>{
const weiboHotUrl = "https://s.weibo.com/top/summary?cate=realtimehot";
const browser = await puppeteer.launch({
headless: true,
// executablePath: "C:\\Program Files\\Google\\Chrome\\Application\\chrome.exe",
executablePath: '/usr/bin/chromium-browser',
args: ['--no-sandbox']
});
try {
const page = await browser.newPage();
await page.goto(weiboHotUrl);
await page.waitForSelector('#pl_top_realtimehot tbody>tr .td-02');
const tds = await page.$$('#pl_top_realtimehot tbody>tr .td-02');
const list = await Promise.all(tds.slice(1).map(async (td, i) => {
const list1 = await td.$eval('a', a => ({
title: a.innerText,
url: `https://s.weibo.com${a.getAttribute('href')}`,
}));
const list2 = await td.$eval('span', span => ({
hot: span.innerText
}));
return {id: i + 1,...list1,...list2};
}));
return list;
} catch (e) {
console.error(e);
} finally {
await browser.close(); // 关闭浏览器避免服务器资源的浪费
}
}
7.设置定时任务
// 每5分钟执行一次 爬取微博热搜
schedule.scheduleJob('*/5 * * * *', async ()=>{
const res=await get_weibo_hot();
await redis.set('weibo_hot',JSON.stringify(res)); // 把数据存入redis
});






